
Bab 3: Harapan Hidup
Bab 3: Harapan Hidup
Bab ini adalah Pengantar Konsep Dasar tentang Harapan Hidup.
3A: Banyak Jenis Angka
Dipercayai secara populer bahwa "Anda tidak dapat berdebat dengan angka". Berlawanan dengan kepercayaan populer ini, ada banyak jenis Angka:
- Kualitatif dan Tak Terukur: Korupsi, Cinta, Kecerdasan, Keberanian, Simpati, dst. Seseorang dapat mengukur manifestasi, seperti jumlah artikel untuk kualitas penelitian. Angka-angka seperti ini dapat berbahaya karena mengalihkan perhatian dari kenyataan menuju manifestasi.
- Kuantitatif, Multidimensi: Kekayaan Material, Ukuran Tubuh – ini adalah hal-hal yang dapat diukur, tetapi ada banyak pengukuran berbeda yang diperlukan. Ketika beberapa pengukuran numerik direduksi menjadi satu angka, ia selalu melibatkan pemilihan faktor dan bobot yang subjektif. Dalam kasus seperti ini, angka adalah campuran hal-hal subjektif dan objektif, kombinasi fakta dan nilai. Angka ini dapat berguna jika tujuan pengukuran jelas, dan nilai dimunculkan secara eksplisit.
- Kuantitatif Satu Dimensi: Angka-angka ini sangat penting, karena memberikan ukuran objektif dari unsur-unsur realitas eksternal.
Aspek Esensial Metodologi Islam
Ketika kita menanyakan empat pertanyaan tentang mengapa, bagaimana, makna, dan dampak dari angka, tidak mungkin berbicara tentang angka secara abstrak. Pertanyaan-pertanyaan ini HANYA dapat dijawab ketika kita berbicara tentang angka yang digunakan dalam konteks dunia nyata tertentu. Jadi, kita menolak pemisahan teori dan praktik, dan berpendapat bahwa teori hanya dapat dipahami dalam konteks aplikasi dunia nyata.
Dalam bagian ini, kita akan membahas angka yang digunakan untuk mengukur Harapan Hidup (LE). LE adalah ukuran yang berguna dari sebuah aspek nyata dan penting dalam kehidupan pribadi kita. Jumlah waktu yang tersisa bagi kita untuk hidup sangat penting bagi kita merencanakan masa depan, dan menentukan bagaimana kita hidup di masa sekarang.
Pertanyaan Kunci
Mengapa kita mempelajari Harapan Hidup? Tidak seperti GNP dan ukuran-ukuran lain yang merupakan campuran subjektif dan objektif, LE memberikan pemeringkatan objektif atas negara-negara sehubungan satu dimensi kesehatan.
Apa yang dimaksud dengan angka Harapan Hidup? Secara kasar, ia adalah jumlah rata-rata waktu yang dapat diharapkan seseorang untuk hidup.
Bagaimana angka LE dihitung? Aspek ini akan dibahas secara terperinci nanti.
Jenis dampak apa yang dapat ditimbulkan dari mempelajari angka-angka ini di dunia nyata? Peningkatan LE sering sesuai dengan peningkatan kesehatan dan gizi untuk populasi umum. Untuk memahami bagaimana hal ini penting, saya merujuk ke artikel yang baru-baru ini diterbitkan: “Harapan Hidup dan Tingkat Kematian di Amerika Serikat, 1959-2017” oleh Woolf & Schoomaker. Artikel ini menyatakan bahwa, setelah meningkat terus menerus dari tahun 1959 hingga 2014, dari 69,9 menjadi 80, LE telah menurun selama tiga tahun berturut-turut! MENGAPA harapan hidup mulai MENURUN di AS, bertentangan dengan pola global? Studi ini menelusuri sumber penurunan kepada peningkatan kematian usia paruh baya. Orang paruh baya di AS mengalami peningkatan angka kematian karena minuman keras, obat-obatan, dan depresi yang mengarah ke bunuh diri. Karena Harapan Hidup meningkat di seluruh dunia dan juga meningkat pada kelompok usia LAIN di AS, statistik ini menandakan sesuatu yang sangat salah dengan KEHIDUPAN pada usia paruh baya di AS. Statistik ini menunjukkan aspek dunia nyata yang layak dipelajari lebih lanjut secara lebih rinci.
Menggunakan Harapan Hidup sebagai Proksi untuk Kesehatan
Sementara menilai "kesehatan" itu sulit karena sifatnya yang kualitatif, LE memberikan proksi numerik kuantitatif yang berguna. Dengan menggunakan proksi ini, kita dapat mengajukan pertanyaan seperti berikut:
- Negara mana yang mengalami peningkatan pesat?
- Negara mana yang berkinerja baik?
- Negara mana yang berkinerja buruk, dalam hal penyediaan kesehatan dan gizi yang memuaskan bagi rakyatnya?
Statistik Harapan Hidup tersedia dan memberikan informasi terkait pertanyaan-pertanyaan ini.
Apa MAKNA harapan hidup?
LE didefinisikan sebagai “Usia rata-rata yang DAPAT DIHARAPKAN seorang bayi yang baru lahir untuk hidup”. Definisi ini tidak masuk akal – setiap orang akan hidup sampai usia tertentu – bagaimana kita bisa menghitung RATA-RATA usia mereka?
SOLUSI: Ambil 1000 orang. Untuk setiap orang hitung usia, untuk mendapatkan A(1), A(2), …, A(1000). Sekarang ambil rata-ratanya. Jumlah semuanya adalah TOTAL usia seluruh populasi yang masih hidup, dibagi jumlah total bayi yang baru lahir. Ini adalah usia rata-rata 1000 orang yang lahir hari ini. Saya menjelaskan hal ini dengan Contoh Hipotetis Perhitungan Harapan Hidup:
Dari 1000 orang 850 bertahan hidup sampai 10 tahun, 150 orang meninggal dalam usia 0-10 tahun. Untuk 150 orang ini, total usia gabungan adalah 150 x 5 = 750 tahun. Ini dengan asumsi kasar bahwa mereka semua hidup tepat 5 tahun, titik tengah kategori 0-10 tahun.
Dari 850 orang yang hidup dalam kategori 10-20 tahun, 500 orang bertahan hidup hingga 20 tahun. 350 orang meninggal pada usia rata-rata 15 tahun. Total usia 350 orang ini adalah 350 x 15 = 5250 orang-tahun.
Dari 500 orang yang masih hidup dalam kategori 20-30 tahun, hanya 100 yang bertahan hidup hingga 30 tahun. 400 orang meninggal pada usia rata-rata 25 tahun. Total usia orang yang meninggal dalam kategori ini adalah 400 x 25 = 10.000 orang-tahun.
Akhirnya, dari 100 orang yang masih hidup dalam kategori usia 30-40 tahun, semuanya meninggal dalam kisaran usia ini. Jadi 100 orang berusia rata-rata 35, dengan total usia 100 x 35 = 3500 orang-tahun
Jadi, TOTAL Kehidupan dalam orang-tahun dari 1000 orang adalah 750 + 5250 + 10,000 + 3500 = 19500. Bagi dengan 1000 untuk mendapatkan angka Harapan hidup 19,5. Ini adalah usia rata-rata seluruh populasi ini (1000 orang). Ada statistik lain yang juga berguna mengukur "rata-rata". Ia disebut MEDIAN, atau Waktu Paruh dalam konteks partikel atom. Ia dijelaskan di bawah ini:
Harapan Hidup MEDIAN, juga disebut Waktu Paruh
Dalam contoh di atas, 150 orang meninggal pada usia < 10, 350 orang meninggal pada usia < 20, 400 orang pada usia < 30, dan 100 orang pada usia < 40. Jadi setengah dari populasi (500 orang) meninggal pada usia < 20. Setengah lainnya, 500 orang meninggal pada usia > 20. Jadi usia 20 membagi populasi menjadi dua. Setengah meninggal pada usia kurang dari 20 tahun, dan tepat setengahnya hidup setelah usia 20 tahun. Jadi, harapan hidup MEDIAN, atau waktu paruh dari populasi 1000 orang ini adalah 20. Cara lain mengatakan hal ini adalah dengan bertanya: "berapa harapan hidup seseorang yang dipilih secara acak dari populasi 1000 orang ini?". Untuk orang yang dipilih secara acak, ada 50% kemungkinan kematian sebelum berusia 20 tahun dan 50% kemungkinan meninggal setelah berusia 20 tahun. Ini adalah cara lain untuk menentukan harapan hidup rata-rata, atau waktu paruh. Perhatikan bahwa angka ini mendekati angka 19,5 RATA-RATA, tetapi agak berbeda dalam makna dan metode perhitungannya.
Bagaimana MENGHITUNG Harapan Hidup?
Harapan hidup membutuhkan informasi yang tidak kita miliki. Untuk kumpulan 1000 orang BARU LAHIR, kita perlu MEMPREDIKSI berapa % yang akan mati sebelum berusia 10 tahun, berapa % sebelum berusia 20 tahun, berapa % sebelum berusia 30 tahun, dst. NAMUN angka-angka ini tidak diketahui. Kita tidak tahu berapa banyak bayi baru lahir yang akan meninggal sebelum ulang tahun ke-10 mereka. Metode standar untuk membuat prediksi ini adalah dengan menggunakan tingkat kematian SAAT INI. Artinya, lihatlah persentase penduduk berusia 0-10 tahun yang meninggal pada tahun berjalan, dan gunakan angka itu untuk meramalkan kematian bayi yang baru lahir. Demikian pula, kita dapat menemukan angka kematian penduduk saat ini yang berusia 10-20 tahun, dengan melihat berapa persentase orang dalam rentang usia ini yang meninggal pada tahun berjalan. Kemudian kita dapat menggunakan persentase ini sebagai perkiraan apa yang akan terjadi pada bayi baru lahir yang mencapai kategori usia 10-20 tahun setelah 10 tahun berlalu. Sebuah "tabel mortalitas" memberi kita persentase kematian di setiap kategori usia:
Lihat data tahun 2019, Berapa orang berusia 10-19 tahun yang meninggal? Berapakah jumlah penduduk pada rentang usia 10-19 tahun? Rasio kematian terhadap jumlah penduduk ini adalah angka MORTALITAS untuk orang berusia 10-19 tahun.
Harapan Hidup dihitung dengan menggunakan tingkat kematian saat ini untuk memprediksi kematian di masa depan.
Kesimpulan
Metode standar untuk pemeringkatan negara menggunakan GNP per kapita. Namun, angka ini merupakan campuran dari nilai subjektif yang mengarah pada pemilihan faktor dan bobot yang ditetapkan untuk perhitungan angka ini. Tabel WDI memberikan setidaknya 7 varian dari faktor dan bobot ini dan banyak lagi varian yang dapat dibuat. Angka-angka ini arbitrer karena didasarkan campuran fakta tentang negara, dan nilai-nilai yang digunakan untuk memilih fakta yang akan disorot, dan bobot yang digunakan untuk memprioritaskan faktanya.
Sebaliknya, perbandingan Harapan Hidup adalah indikator objektif dari fakta tentang realitas eksternal. Ini karena kita menghitung ukuran SATU-DIMENSI dari fakta kuantitatif dan numerik tentang suatu negara. Siapa pun yang mencoba menghitung angka ini, menggunakan metode apa pun yang masuk akal, akan mendapatkan angka yang sama. Angka ini adalah fitur negara tersebut, dan bukan proyeksi saya tentang bagaimana mengevaluasi negara tersebut. Pada saat yang sama, harapan hidup bukanlah ukuran sempurna dari jumlah target yang kita coba perkirakan – rata-rata usia hidup bayi yang baru lahir.
Ini karena Harapan Hidup bergantung pada perkiraan tingkat kematian di masa depan dengan tingkat kematian saat ini - perkiraan ini mungkin tidak valid karena banyak kemungkinan - tingkat kematian di masa depan tidak diketahui. Angka LE adalah PERKIRAAN yang wajar tentang harapan hidup.
3B Perhitungan Harapan Hidup dari Tabel Mortalitas
Dalam Bagian B bab ini, kita menjelaskan secara rinci bagaimana harapan hidup dihitung menggunakan contoh hipotetis.
Sebuah Tabel Mortalitas
Untuk menghitung harapan hidup, kita mulai dengan membuat tabel mortalitas. Lihat di bawah ini:
| Kelompok Usia | Jumlah pada 2017 | Mortalitas | Tingkat |
| 0-9.999 | 30J | 6J | 20% |
| 10-19.999 | 40J | 10J | 25% |
| 20-29.999 | 25J | 15J | 60% |
| 30-39.999 | 15J | 10J | 66.67% |
| 40-49.999 | 5J | 5J | 100% |
PAda masing-masing dari 5 kategori kelompok usia, kita MENGASUMSIKAN besaran populasi seperti yang tercantum dalam tabel – J adalah singkatan dari Juta. Jadi ada 30, 40, 25, 15, dan 5 Juta orang dalam kategori usia 0-10, 10-20, 20-30, 30-40, dan 40-50 tahun. Dengan mengumpulkan data kematian menurut kategori usia pada tahun 2017, kita dapat mengetahui jumlah kematian pada setiap kategori usia. Angka ini (hipotetis) tercantum di kolom ketiga. Kolom terakhir memberikan angka kematian di setiap kategori usia, yang hanyalah berupa persentase kematian dalam kategori usia tersebut. Ini disebut tabel mortalitas.
Dari Mortalitas ke Harapan Hidup
| Kelompok Usia | Jumlah Hidup di Awal | Tabel Mortalitas | Jumlah Kematian dalam Periode | Total Masa Hidup |
| 0-9.999 | 1000 | 20% | 200 | 1000 |
| 10-19.999 | 800 | 25% | 200 | 3000 |
| 20-29.999 | 600 | 60% | 360 | 9000 |
| 30-39.999 | 240 | 67% | 160 | 5600 |
| 40-49.999 | 80 | 100% | 80 | 3600 |
| SUM= | 18,600 |
Untuk menghitung Harapan Hidup saat lahir, kita melakukan eksperimen pikiran. Bayangkan 1000 orang yang semuanya lahir pada tanggal 1 Januari 2018 – berapa usia rata-rata mereka? Ini adalah harapan hidup. Kita menggunakan tabel mortalitas untuk MEMPERKIRAKAN bahwa 20% dari orang-orang ini akan mati dalam kategori 0-10 tahun – yaitu, 200 orang akan mati sebelum mencapai ulang tahun ke-10 mereka. Sekarang kita bertanya: berapa lama orang-orang ini hidup secara kumulatif? Kita mengasumsikan bahwa 200 kematian ini terdistribusi SAMA selama 10 tahun, sehingga ada 20 kematian setiap tahun. Dengan asumsi ini, usia rata-rata kesemua 200 orang ini akan menjadi 5 tahun, titik tengah kategori usia 0-10 tahun. Artinya total masa hidup 200 orang yang meninggal ini adalah 200 x 5 = 1000 orang-tahun. Perhitungan ini memberikan angka-angka di baris pertama tabel.
Untuk baris kedua, kita mulai dengan 800 orang yang selamat dari kumpulan 1000 bayi yang baru lahir, yang semuanya berulang tahun pada tanggal 1 Januari 2018. Sekarang adalah tanggal 1 Januari 2018, dan sepuluh tahun telah berlalu. 200 orang dalam kelompok ini telah meninggal, dan 800 masih hidup pada tanggal ini. Berapa banyak yang akan bertahan dari tahun 2018 hingga 2028, dan masuk ke dalam kategori usia 20-30 tahun? Angka kematian anak usia 10-20 tahun yang kita lihat pada tahun 2017 adalah 25%, dan angka ini adalah perkiraan terbaik kita untuk apa yang mungkin terjadi di masa depan. Dengan menerapkan angka ini, kita memperkirakan 25% dari 800 orang ini akan mati, yaitu 200 kematian. Berapa lama 200 orang ini akan hidup secara kumulatif? Dengan asumsi distribusi kematian yang sama selama sepuluh tahun, usia rata-rata kelompok ini adalah 15 tahun, titik tengah kategori 10-20 tahun. Ini memberi kita 3000 orang-tahun yaitu 15 tahun dikali 200 orang, sebagai total masa hidup 200 orang. Perhitungan ini memberi kita angka-angka di baris kedua tabel, untuk kelompok usia 10-20 tahun.
Kita dapat melanjutkan ke baris ketiga dan menghitungnya dengan cara yang sama. 600 orang akan hidup pada tanggal 1 Januari 2038 dan masuk ke dalam kategori usia 20-30 tahun. Angka kematian dalam kategori ini pada tahun 2017 adalah 60%. Menerapkan tingkat ini ke masa depan, kita berasumsi bahwa 60% dari 600 orang dalam kategori usia 20-30 tahun ini akan meninggal sebelum tanggal 1 Januari 2048. Jadi, total masa hidup 360 orang yang akan meninggal adalah 360 x 25 = 9000 orang-tahun.
Melanjutkan hitungan seperti ini, 240 orang akan hidup pada tanggal 1 Januari 2048, dan akan masuk ke dalam kategori usia 30-40 tahun. Angka kematian sebesar 66,67% untuk kategori usia ini pada tahun 2017 membuat kita memperkirakan bahwa 160 dari orang-orang ini akan meninggal sebelum mencapai tanggal 1 Januari 2058. Usia rata-rata 160 orang ini adalah 35 tahun, sehingga total masa hidup pada kategori ini adalah 160 x 35 = 5600 orang-tahun. Hanya 80 orang yang akan hidup sampai tanggal 1 Januari 2068 dalam kategori usia 40-50 tahun. Kita berasumsi 100% kematian pada kelompok usia ini, jadi semua orang akan mati. Total masa hidup dari kategori terakhir ini adalah 80 x 45 = 3600 orang-tahun.
Sekarang harapan hidup dapat dihitung dengan menjumlahkan semua total masa hidup dari 1000 orang ini. Jumlah semuanya adalah 18.600 orang-tahun. Jika masing-masing dari 1000 orang hidup tepat 18,6 tahun, maka jumlah totalnya juga akan menjadi 18.600, jadi 18,6 tahun adalah usia rata-rata 1000 orang ini. Ini adalah angka harapan hidup.
Median atau Waktu Paruh
Daripada masa hidup rata-rata, kita juga dapat menggunakan masa hidup median sebagai ukuran harapan hidup. Masa hidup median untuk 1000 orang ini adalah tanggal di mana 500 orang meninggal, sementara 500 orang tetap hidup. Ini dapat dihitung dengan mudah dari tabel sebelumnya. Dalam dua kategori usia pertama, dari 0-10 dan 10-20 tahun, terjadi 400 kematian. Dalam kategori 20-30 tahun berikutnya, terjadi 360 kematian, sehingga kematian kumulatif pada akhir periode ini adalah 760 orang. Jelas, kematian ke-500 akan terjadi dalam kategori usia ini. Kita tahu bahwa 600 orang memasuki kategori usia 20-30 tahun pada tanggal 1 Januari 2038. Kita tahu bahwa 360 orang dari mereka akan mati dalam dekade berikutnya, antara tanggal 1 Januari 2038 dan 1 Januari 2048. Usia median adalah tanggal di mana orang ke 500 meninggal. 400 orang telah meninggal lebih awal dalam kategori usia sebelumnya. Jadi kematian ke-500 akan menjadi kematian ke-100 dalam kategori ini. Sebanyak 360 kematian akan terjadi selama sepuluh tahun. Jadi kematian ke-100 akan terjadi pada waktu yang proporsinya 100/360 dari periode 10 tahun ini, dengan asumsi kematian tersebar merata selama dekade ini. Jadi, (100/360) * 10 thn = 2,777 thn sehingga masa hidup median adalah 22,777 tahun, yang merupakan perkiraan usia orang ke-500 yang meninggal dalam kategori ini.
Penyempurnaan: Kematian yang Sama vs Probabilitas yang Sama
Perhitungan di atas hanyalah upaya kasar awal untuk menjelaskan rincian perhitungan harapan hidup, menurut metode "periode harapan hidup". Ada metode lain, seperti metode “angkatan”, yang juga dapat digunakan. Diskusi tentang angka masa hidup dan maknanya diberikan dalam "Harapan Hidup" – Apa makna sebenarnya? oleh Esteban Ortiz-Ospina di situs Bank Dunia pada tanggal 28 Agustus 2017. Terlepas cara kita melakukan perhitungan, harapan hidup bergantung pada ekstrapolasi tentang masa depan berdasarkan apa yang telah kita amati di masa lalu. Masa depan secara inheren tidak pasti, dan karenanya proyeksi seperti ini tidak pernah bisa dibuat dengan akurat. Yang terbaik adalah menerima ketidakpastian, dan menggunakan metode sederhana, daripada menggunakan metode rumit untuk menciptakan ilusi kecanggihan dan akurasi yang tidak dapat dicapai ketika menebak tentang masa depan.
Ada satu penyempurnaan yang terkadang menjadi penting, dan layak untuk dijelaskan dan diklarifikasi. Proyeksi kita, seperti yang dihitung di atas, didasarkan pada asumsi bahwa jika ada 200 kematian selama 10 tahun, maka ia terdistribusi secara merata selama 10 tahun, sehingga ada 20 kematian setiap tahun. Untuk kategori usia 0-10 tahun, kita dapat merincinya sebagai berikut:
| Usia | Penyintas | Kematian | Tingkat |
| 0-1 | 1000 | 20 | 2.00% |
| 1-2 | 980 | 20 | 2.04% |
| 2-3 | 960 | 20 | 2.08% |
| 3-4 | 940 | 20 | 2.13% |
| 4-5 | 920 | 20 | 2.17% |
| 5-6 | 900 | 20 | 2.22% |
| 6-7 | 880 | 20 | 2.27% |
| 7-8 | 860 | 20 | 2.33% |
| 8-9 | 840 | 20 | 2.38% |
| 9-10 | 820 | 20 | 2.44% |
| 200 |
Menyamakan jumlah kematian menyebabkan meningkatnya kemungkinan kematian. Sebagai alternatif, adalah mungkin menyamakan probabilitas kematian, yang akan membuat jumlah kematian menurun. Tidaklah mungkin lebih menyukai satu metode dibanding yang lain berdasarkan teori. Solusi terbaik adalah melihat data untuk benar-benar mendapatkan tingkat kematian dalam kategori 1 tahun dan menghindari perkiraan teoretis. Namun alasan menyebutkan hal ini adalah terkadang kematian tertinggi terjadi pada kategori usia 0-1 tahun. Begitu orang bertahan hidup sampai satu tahun, maka angka kematian turun drastis. Dalam kasus seperti ini, asumsi kematian yang sama, atau probabilitas kematian yang sama, keduanya bisa menyesatkan.
Tujuan saya dalam bagian ini bukan untuk menjadikan pelajar ahli dalam bidang demografi, dan dalam mempelajari metode perhitungan angka harapan hidup. Sebaliknya, saya memberikan perincian yang cukup untuk memastikan pelajar merasa nyaman dengan konsep itu, dan memahami bagaimana ia dihitung dan apa maknanya. Penting dicatat bahwa meskipun harapan hidup adalah perkiraan tentang masa depan, ia didasarkan pada data saat ini. Artinya ia mencerminkan realitas kematian saat ini, dan memberi kita informasi yang berguna tentang kesehatan penduduk saat ini, yang dikemas dalam satu angka.
3C Menganalisis Data Bank Dunia tentang Harapan Hidup
Bagian C bab 3 buku ini memulai analisis kumpulan data WDI (Indikator Pembangunan Dunia) Bank Dunia, yang mencakup 190 negara dari tahun 1960 hingga 2018. Tujuan analisis kita berbeda dari tujuan analisis konvensional. Sir Ronald Fisher, yang juga dikenal sebagai bapak statistika, mendefinisikan statistika sebagai pereduksian data. Sebaliknya, pendekatan Islami berupaya menghasilkan ilmu yang bermanfaat, daripada bermain-main dengan angka. Jadi, kita bertujuan menggunakan angka untuk belajar tentang dunia nyata. Untuk tujuan ini, penting memilih angka yang menyampaikan informasi tentang dunia nyata. Harapan Hidup adalah salah satu angka ini, yang merupakan informasi objektif tentang kondisi kehidupan di negara mana pun. Ia berbeda dengan data seperti GNP per kapita, yang merupakan campuran pendapat subjektif tentang kekayaan, dan faktor apa yang dianggap relevan atau tidak relevan untuk tujuan ini, bersama data sejati tentang dunia nyata. Karena campuran fakta dan nilai ini, banyak angka mencerminkan pola pikir pencipta angka, bukan fakta tentang realitas eksternal. Untuk statistika konvensional, tidak masalah jenis angka yang kita miliki, dan kaitan angka tersebut dengan realitas eksternal. Mengambil kesimpulan dari angka-angka ini melibatkan kumpulan operasi yang sama. Tapi untuk pendekatan Islam, ada perbedaan besar, karena angka yang mencerminkan pola pikir subjektif tidak akan membantu kita belajar tentang realitas eksternal. Video yang ditautkan di bawah memberikan langkah pertama belajar tentang kumpulan data harapan hidup ini, dan apa yang diberitahunya kepada kita tentang dunia nyata.
==== LAPORAN (juga: lampirkan lembar kerja dalam 3D)
Salah satu pelajaran penting yang disampaikan bagian ini adalah pentingnya tolak ukur untuk perbandingan. Jika kita ingin menilai kinerja negara mana pun, kita harus MEMBANDINGKAN kinerja ini dengan sesuatu — sesuatu ini adalah “tolok ukur” kinerja. Kita mulai dengan membuat tiga tolok ukur. Minimum, Maksimum, dan Median. Dengan menggunakan tiga angka ini kita dapat melihat negara mana pun dan menempatkannya pada bagian bawah atau bagian atas sehubungan Angka Harapan Hidup. Kita juga dapat menilai seberapa dekat negara itu dengan negara peringkat teratas dan terbawah untuk mendapatkan gambaran tentang posisinya di antara 190 negara yang datanya telah ditabulasi. Perbandingan tersebut memungkinkan kita menilai kinerja, apakah baik, buruk, atau rata-rata, dari negara tersebut. Setiap kali kita mengatakan X itu baik atau buruk, kita MEMBANDINGKAN kinerja X dengan sesuatu yang lain. Agar jelas, penting menyatakan dengan apa X dibandingkan untuk mengevaluasi kinerjanya. Memilih tolok ukur, dan menjustifikasinya adalah salah satu aspek penting dari retorika statistik, sebuah metodologi di mana angka digunakan untuk mempengaruhi.
3D Histogram untuk Data Harapan Hidup Bank Dunia
Sedikit Latar Historis: Bagaimana cara kita menganalisis kumpulan data yang besar? Data LE tahunan untuk 190 negara pada tahun 1960-2017, yaitu 57 tahun x 190 negara, menghasilkan lebih dari 10.000 poin data?
Jawaban Klasik: Temukan model teoretis perkiraan untuk data ini. Sesuaikan data dengan model, lalu analisis ciri-ciri model. Ini "mereduksi" data dan menggantinya dengan model teoretis dengan beberapa parameter, dan membuatnya mudah untuk dipahami dan dianalisis. Tapi MENGAPA metode ini digunakan, yang sekarang tampak alami bagi ahli statistika? KARENA Kemampuan Komputasi untuk melakukan jenis analisis yang benar dulu TIDAK ADA!
Saat ini, Statistika terjebak dalam perangkap teori – Kemampuan Komputasi yang diperlukan untuk analisis data yang baik telah muncul – meskipun baru belakangan ini. Pedagogi BELUM mengejar ketertinggalan ini. Kita masih mengajar statistika seperti ketika belum ada komputer.
Apa TUJUAN dari analisis data statistik?
- PERTAMA: untuk MEMAHAMI kumpulan data – apa yang dikatakan 190 x 57 angka LE kepada kita?
- KEDUA: untuk melacak implikasi angka ini bagi realitas
MASALAH – Pikiran kita TIDAK dapat memahami data mentah yang berupa tabel 190 x 57 angka. Kita tidak dapat melihat pola dalam data ini. Kita bahkan tidak dapat menemukan minimum, maksimum, atau membandingkan dan mengevaluasi negara, menggunakan TABEL tersebut secara langsung.
SOLUSI – TEMUKAN cara merepresentasikan data yang masuk akal bagi PIKIRAN kita. Kita mencari GUI – Antarmuka Pengguna Grafis – untuk mengakses data. Sebelum Komputer, model teoretis bagi data adalah SATU-SATUNYA pendekatan yang mungkin untuk mereduksi data. BANYAK usaha telah dilakukan tentang BAGAIMANA menyesuaikan model teoretis dengan data. Statistika konvensional HANYALAH TENTANG menyesuaikan model teoritis bagi data. “Pendekatan Radikal” kita didasarkan pada MENGUBAH tujuan – daripada membuat model teoretis untuk mewakili data dalam bentuk yang “lebih mudah” dipahami, kita mencoba LANGSUNG memahami data itu SENDIRI! Bagian ini akan membahas salah satu alat terbaik yang memungkinkan kita melihat data secara langsung: HISTOGRAM.
Bagaimana kita membuat histogram? Kategorikan data, dan lihat angka dalam setiap kategori. Misalnya, kita memiliki data demografis suatu populasi yang diklasifikasikan berdasarkan usia. Kita dapat menghitung jumlah orang dalam kategori usia berikut: 0-10 anak-anak, 11-20 remaja, 20-40 angkatan kerja yang lebih muda, 40-60 angkatan kerja yang lebih tua, 60+ pensiunan. Masing-masing kategori ini disebut "bin". Banyak cara lain untuk mengkategorikan data. GAMBAR data yang membagi data ke dalam kategori, dan MENGHITUNG jumlah poin di setiap kategori, disebut HISTOGRAM. Dalam bagian ini, kita akan MEMBUAT, menafsirkan, dan menganalisis histogram data harapan hidup.
Bagian MEMBUAT mudah karena EXCEL sekarang memiliki tipe Grafik Histogram bawaan. Ia tidak tersedia pada versi sebelumnya, dan cukup lamban dan sulit membuat histogram sebelum tahun 2016. Sekarang, cukup soroti kolom (atau baris) angka, dan klik pada tipe grafik Histogram untuk membuatnya. Di bawah ini adalah Histogram Harapan Hidup pada tahun 1960. Data untuk 190 negara dimasukkan ke 6 bin dari [20,30) dalam kategori sepuluh tahun hingga ke [70,80). Sebagai konvensi notasi “[” berarti penyertaan, sedangkan “)” berarti pengecualian; [20,30) yang berarti semua usia dari 20 tahun sampai, tapi tetapi tidak termasuk, 30 tahun. Histogram ditunjukkan di bawah ini. Seluruh kumpulan data WDI Bank Dunia tentang Harapan Hidup tersedia melalui tautan pendek: http://bit.ly/rsraC3LE. Pelajar dapat memeriksa lembar kerja dan menggunakan EXCEL untuk mereplikasi histogram ini. Instruksi disediakan pada lembar kerja EXCEL.

Apa yang kita pelajari dari histogram ini? Istilah teknis berguna untuk melanjutkan analisis ini. MODAL BIN (singkat: MODUS) berisi jumlah titik data terbesar. Dari gambar diatas terlihat bahwa MODUS terjadi pada range [60,70). Ada 60 negara dalam kategori usia ini, lebih banyak dari kategori lainnya. Artinya mayoritas negara (60) memiliki harapan hidup pada kisaran 60 sampai 70 tahun pada tahun 1960. Ada beberapa negara (12) yang memiliki harapan hidup lebih tinggi pada kisaran 70-80 tahun. Ada dua negara yang memiliki harapan hidup di bawah 30 tahun. Histogram tidak memberi tahu kita negara mana di bin mana, tetapi kita dapat mempelajarinya dengan kembali ke data aslinya. 6 negara terbawah adalah:
| Mali | 28.199 |
| Yemen, Rep. | 29.919 |
| Sierra Leone | 31.566 |
| South Sudan | 31.697 |
| Gambia, The | 32.054 |
| Afghanistan | 32.446 |
Cara kita membuat bin adalah arbitrer, yang memungkinkan kita mendistorsi data, dan mengemukakan argumen yang salah. Misalnya, bin paling bawah untuk usia 20 hingga 30 tahun hanya berisi dua negara, Mali dan Yaman, dengan harapan hidup masing-masing 28,1 dan 29,9 tahun. Dari histogram, orang bisa mendapatkan kesan bahwa kedua negara ini memiliki harapan hidup yang sangat rendah. Meskipun negara-negara ini berada di bawah, melihat negara-negara terdekat, kita melihat bahwa tidak ada batas yang jelas antara negara-negara ini dan yang sedikit di atas mereka. Faktanya, ada sekitar 12 negara dalam kisaran 28 hingga 35. Negara-negara ini memiliki harapan hidup terendah dalam kumpulan data, tetapi mereka semua dekat satu sama lain, dan tidak ada yang bisa disebut luar biasa dalam kelompok ini.
Modus global adalah bin dengan jumlah titik data terbesar di dalamnya. Dengan ukuran bin yang telah ditentukan, kita melihat bahwa kategori [60,70) adalah modus global. Konsep modus "lokal" juga penting dalam memahami kumpulan data. Modus lokal adalah bin yang memiliki lebih banyak data daripada bin tetangganya di kedua sisi. Dalam kumpulan data di atas, bin [40,60) adalah modus lokal dengan 50 negara, lebih banyak dari bin tetangga [30,40) dan [60,70). Ketika histogram memiliki dua modus, ia disebut bimodal. Kumpulan data bimodal MENYARANKAN hipotesis tentang dunia nyata: ada dua jenis negara yang berbeda, negara dengan Harapan Hidup rendah dan negara dengan Harapan Hidup tinggi. Ini hanya perkiraan berdasarkan gagasan tentang bagaimana data cenderung didistribusikan, tetapi juga didukung fakta yang terkenal bahwa ada kesenjangan besar antar negara dari segi kekayaan. Masuk akal bahwa harapan hidup akan tinggi di negara-negara kaya dan rendah di negara-negara miskin. Namun, hipotesis alami ini mengarah pada teka-teki. Negara-negara kaya sedikit jumlahnya sedangkan negara-negara miskin jauh lebih banyak. Jika kekayaan dan harapan hidup berkorelasi sangat tinggi, kita akan berharap melihat modus tinggi dengan harapan hidup rendah, dan modus yang lebih kecil dengan harapan hidup tinggi. Nyatanya grafik menunjukkan sebaliknya. Untuk menyelidiki perbedaan ini, kita perlu melihat negara-negara dalam dua modus, dan mencoba mencari faktor-faktor yang membedakan mereka. Kita akan mencari faktor-faktor yang relevan dengan peningkatan/penurunan harapan hidup.
Ini membawa kita ke perbedaan metodologis utama antara statistika "riil", dan pendekatan konvensional. Statistika riil melibatkan tindakan bolak-balik antara melihat analisis data dan aspek kualitatif dari dunia nyata. Analisis data di atas menunjukkan bahwa ada perbedaan yang signifikan dalam harapan hidup antar negara. Tetapi data tidak dapat memberi tahu kita MENGAPA? Untuk mempelajari alasannya, kita harus melampaui kumpulan data, dan mencoba memahami fitur dunia nyata apa yang menyebabkan perbedaan ini. Setelah kita menangani faktor-faktor yang relevan, maka kita dapat kembali mencoba mengukur dan mengkuantifikasi faktor-faktor ini, untuk menilai seberapa penting faktor-faktor ini dalam menjelaskan perbedaan harapan hidup. Keberhasilan atau kegagalan dalam proses ini akan membawa kita pada pemahaman yang lebih dalam tentang penyebab tingginya angka harapan hidup, dan mungkin memberikan kita panduan tentang kebijakan yang dapat kita ambil untuk meningkatkan harapan hidup. Penting disadari bahwa menghitung angka tanpa menganalisis dunia nyata tidak bisa mengarah pada pemahaman yang sama. Seperti yang dikatakan Freedman, memahami penyebab membutuhkan biaya "kulit sepatu" - kita harus berjalan-jalan di dunia nyata untuk memahami penyebab harapan hidup yang lebih tinggi. Sementara statistika konvensional memberi tahu kita bahwa kita mempelajari data untuk sampai pada kesimpulan tentang dunia nyata, metodologi statistika "riil" memberi tahu kita bahwa kita mempelajari data untuk menghasilkan dugaan tentang dunia nyata. Dugaan ini harus dinilai dengan studi langsung terkait isu-isu dunia nyata yang relevan.
Kita dapat mempelajari perubahan harapan hidup rata-rata negara seiring waktu dengan melihat bagaimana histogram di atas berubah. Untuk tujuan ini, kita mengulangi pembuatan histogram LE untuk tahun 1970:

Histogram ini menunjukkan kemajuan substansial dalam harapan hidup dari tahun 1960 hingga 1970. Jumlah negara dengan LE kurang dari 40 tahun telah berubah dari 31 negara menjadi 14 negara. Modus kedua di [40,50) telah hilang; 50 negara dalam kategori ini telah menyusut menjadi 33 negara. Pengurangan dalam tiga kategori terbawah diimbangi peningkatan dalam tiga kategori teratas. Setiap negara dengan cepat meningkatkan skala harapan hidup. Apa pun faktor yang menyebabkan peningkatan harapan hidup yang substansial ini, faktor-faktor tersebut tersebar luas di seluruh dunia, dan tidak terkonsentrasi di sejumlah kecil negara yang sangat kaya. Orang akan menebak bahwa ketersediaan antibiotik murah yang mudah di seluruh dunia mungkin menjadi bagian penting dari penjelasannya. Untuk memverifikasi faktor ini, seseorang perlu mengumpulkan data tentang bagaimana penggunaan antibiotik telah menyebar seiring waktu, dan apakah perubahan ini paralel dengan peningkatan yang kita lihat dalam harapan hidup. Perlu dicatat bahwa pembelajaran mesin dan analisis mekanis data besar tidak dapat menghasilkan hipotesis tentang faktor-faktor yang berpotensi relevan dan layak dipelajari – yang membutuhkan pemahaman yang lebih dalam tentang dunia nyata. Setelah data dikumpulkan – berdasarkan intuisi dan pengetahuan – maka teknik statistika berperan dalam memverifikasi hipotesis kita tentang penyebab perubahan yang kita amati. Statistika tidak dapat memberi tahu kita data mana yang harus kita kumpulkan.
Akhirnya, kita melihat histogram untuk dekade 1980-an. Terlihat kemajuan berkelanjutan dalam hal peningkatan harapan hidup rata-rata. 3 kategori terbawah, dari 20 hingga 50 tahun, sebelumnya berisi 49 negara, dan sekarang hanya berisi 33 negara – harapan hidup di sebagian besar negara berada di atas 50 tahun. Ada titik data luar biasa yang menarik: kategori [20,30) kosong pada tahun 1970 – harapan hidup di semua negara berada di atas 30 tahun. Tapi sekarang ada satu negara dalam kategori ini. Negara mana itu, dan bagaimana ia jatuh kembali? Melihat kumpulan data, kita dapat mengidentifikasi negara itu sebagai Kamboja, yang berubah dari harapan hidup 42 tahun pada tahun 1970 menjadi hanya 29 tahun pada tahun 1980. Hanya mereka yang mengetahui sejarah Perang Vietnam, serta kebangkitan dan kejatuhan Khmer Merah akan dapat memahami mengapa hal ini terjadi – tidak ada tindakan mengolah angka yang dapat mengungkapkan makna dari perubahan dramatis ini.

Histogram adalah alat statistika konvensional. Ia menghapus semua identitas dalam titik data, dan memperlakukan semua titik data dengan cara yang sama. Metodologi konvensional mengasumsikan bahwa semua titik data diperoleh secara acak dari distribusi umum. Semua titik data dianggap homogen, sehingga memungkinkan memperlakukan semuanya secara kolektif. Ini adalah kekuatan dan kelemahan pendekatan konvensional. Memang benar bahwa memeriksa data secara kolektif dapat mengungkapkan pola yang menarik. Tetapi data juga memiliki kekhasan – setiap titik data memiliki individualitas dan kepribadian – seperti data Kamboja. Dalam statistika "riil", kita memperhatikan kedua-dua gambaran kolektif yang menyeragamkan data, dan kekhasan setiap titik data individu secara terpisah.
Salah satu cara melakukan hal ini dalam konteks kumpulan data saat ini adalah dengan melihat sepuluh negara teratas dan bagaimana mereka telah berubah seiring waktu.
| 1960s Top Ten | 1970s Top Ten | 1980s Top Ten | |||
| Norway | 73.5 | Sweden | 74.6 | Iceland | 76.8 |
| Iceland | 73.4 | Norway | 74.1 | Japan | 76.1 |
| Netherlands | 73.4 | Iceland | 73.9 | Netherlands | 75.7 |
| Sweden | 73 | Netherlands | 73.6 | Sweden | 75.7 |
| Denmark | 72.2 | Denmark | 73.3 | Norway | 75.7 |
| Switzerland | 71.3 | Switzerland | 73 | Switzerland | 75.5 |
| New Zealand | 71.2 | Canada | 72.7 | Spain | 75.3 |
| Canada | 71.1 | Cyprus | 72.6 | Canada | 75.1 |
| United Kingdom | 71.1 | Spain | 72 | Cyprus | 74.8 |
| Australia | 70.8 | United Kingdom | 72 | Hong Kong | 74.7 |
Pola menarik yang tidak terlihat pada angka adalah negara-negara Nordik – Norwegia, Belanda, Swiss, Swedia, Denmark, Islandia di Eropa Utara sangat terwakili. Apa persamaan di antara negara-negara ini yang menyebabkan angka harapan hidup tinggi? Banyak faktor potensial yang patut diselidiki. Munculnya Siprus dalam daftar itu menarik, karena bukan negara berpenghasilan tinggi. Apa yang istimewa dari Siprus yang memungkinkannya masuk dalam jajaran negara-negara 10 besar? Apa bedanya dengan negara lain dalam situasi serupa?
Tabel di atas menunjukkan harapan hidup dari sepuluh negara teratas untuk dekade 60-an, 70-an, dan 80-an. Selanjutnya kita melihat dekade setelah itu.
| 1990s Top Ten | 2000s Top Ten | 2015 Top Ten | |||
| Japan | 78.8 | Iceland | 81.1 | Greece | 84.3 |
| Iceland | 78 | Greece | 80.9 | Iceland | 83.8 |
| Sweden | 77.5 | Israel | 80.4 | Israel | 83.7 |
| Canada | 77.4 | France | 79.8 | Macao SAR | 82.9 |
| Hong Kong | 77.4 | Macao SAR | 79.7 | Switzerland | 82.8 |
| Macao SAR | 77.3 | Japan | 79.7 | Montenegro | 82.7 |
| Switzerland | 77.2 | Canada | 79.6 | France | 82.5 |
| Australia | 77 | Netherlands | 79.2 | Japan | 82.5 |
| Italy | 77 | Australia | 79.1 | Channel Islands | 82.4 |
| Greece | 76.9 | Malta | 79.1 | Netherlands | 82.4 |
Naiknya Yunani ke posisi teratas sangat mengejutkan, terutama karena Yunani telah menderita kesulitan ekonomi yang parah sejak Krisis Keuangan Global. Kita harus mencari penjelasan. Secara umum, ketika anda menemukan statistik yang mengejutkan, ada dua kemungkinan sumber kejutan tersebut. Salah satu kemungkinan adalah kesalahan pengukuran – kita harus melihat dengan cermat bagaimana statistik ini dikompilasi, dan mencari sumber kesalahan yang besar. Kemungkinan kedua adalah bahwa benar-benar ada perubahan dalam sistem kesehatan di Yunani yang menyebabkan lonjakan dari 76,9 tahun pada tahun 1990 menjadi 84,3 tahun pada tahun 2015. Seseorang harus melihat dunia nyata untuk menemukan jawabannya. Aspek statistika riil ini – di mana statistik menimbulkan pertanyaan tentang aspek tertentu dari dunia nyata, dan di mana setiap titik data memiliki sifat yang unik – berbeda secara radikal dari metodologi statistika konvensional yang memperlakukan semua data sebagai sampel acak dari distribusi umum.
Menganalisis perubahan histogram setelah tahun 1980, 1990, 2015
Grafik berikutnya memberikan histogram untuk dekade 1980-an. Kita sekarang melihat bahwa setiap negara memiliki harapan hidup dalam kisaran rata-rata 75-85 tahun. Selanjutnya, kategori 65-75 tahun sejauh ini merupakan kategori terbesar. Ini adalah kategori modus, dengan lebih dari 80 negara di dalamnya. Untuk pertama kalinya, dua negara berada di atas rata-rata 75 tahun dan naik ke kategori 75-85 tahun , yang sebelumnya kosong.

Latihan Lab Komputer yang terkait dengan bab ini akan mengajarkan anda mengekstrak Harapan Hidup untuk semua negara dalam kumpulan data pada dekade 1980-an, 1990-an, dan 2015. Perhatikan perubahan di negara-negara 10 teratas dan 10 terbawah. Juga, temukan peringkat negara-negara tertentu yang kita ikuti seiring waktu, dan catat setiap pembalikan peringkat – negara-negara yang peringkatnya rendah bergerak naik, dan berubah posisi. Pikirkan MENGAPA hal ini bisa terjadi, dan perhatikan bahwa jawaban pertanyaan ini TIDAK akan ditemukan dalam kumpulan data. Ini adalah aspek penting dari “Statistika Riil” – istilah alternatif bagi Pendekatan Islam. Angka-angka yang diperoleh adalah penunjuk realitas, dan bukan objek studi. Pengamatan memberi kita petunjuk tentang aspek-aspek penting dari realitas, dan studi lebih lanjut secara mendalam tentang realitas itu sendiri diperlukan untuk menindaklanjuti petunjuk-petunjuk ini, dan belajar dari angka-angka tersebut.
Periksa tugas anda tentang kumpulan data Harapan Hidup dengan membandingkan histogram anda untuk tahun 1990 dan histogram buku ini untuk tahun 1990, yang ditampilkan di bawah ini.
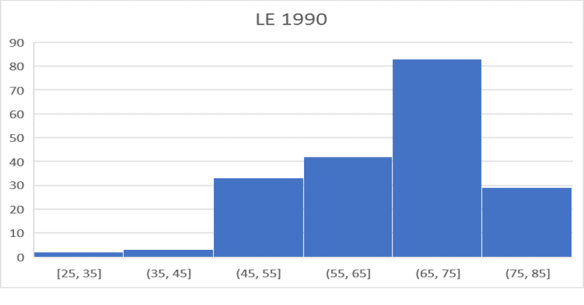
Secara serupa, buat histogram untuk tahun 1990. Urutkan data berdasarkan Harapan Hidup pada tahun 1990 untuk mempelajari negara-negara 10 teratas dan 10 terbawah. Perhatikan juga peringkat relatif negara anda sendiri, serta beberapa negara lain yang sebanding – ikuti peringkat ini seiring waktu. Perhatikan kenaikan Harapan Hidup secara umum di negara-negara terbawah? Mengapa kita mengamati fenomena ini? Bisakah pertanyaan ini dijawab dengan analisis data saja?
Selanjutnya perhatikan histogram untuk tahun 2000 yang diplot di bawah ini:
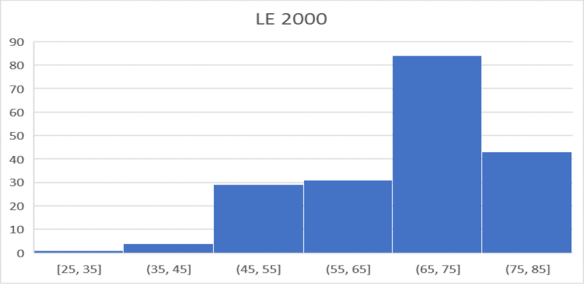
Hitung peringkat semua negara pada tahun 2000. Peringkat ini dapat digunakan untuk mempelajari negara-negara 10 teratas, 10 terbawah, dan peringkat negara-negara tertentu yang kita ikuti. Ada banyak kejutan dalam kumpulan data ini. Secara khusus, kinerja Yunani mengejutkan. Apa yang menyebabkan keberhasilan Yunani dalam meningkatkan harapan hidup, meskipun kesulitan ekonomi serius sedang dihadapi negara itu? Untuk menjawab pertanyaan ini, kita perlu memiliki informasi yang lebih rinci tentang Yunani, dan kebijakan sosial yang mempengaruhi kematian di negara itu. Perhatikan bahwa peningkatan Harapan Hidup harus disebabkan oleh penurunan kematian saat ini dalam berbagai kategori usia. Bagaimana jumlah kematian telah menurun, sebagai persentase dari populasi? Demikian pula perhatikan perilaku negara-negara 10 besar dan 10 terbawah, serta negara-negara lain, dan perhatikan setiap pembalikan yang mengejutkan sebagai fenomena untuk dijelajahi lebih lanjut dengan mempelajari dunia nyata secara lebih mendalam.
Histogram terakhir kita adalah untuk Harapan Hidup pada tahun 2015. Untuk pertama kalinya, kategori [75-85] sekarang menjadi kategori MODUS, dengan jumlah negara terbesar masuk dalam kategori ini. Perhatikan bahwa kategori ini dimulai dengan NOL negara di dalamnya pada dekade 1960-an. Ini menunjukkan bahwa Harapan Hidup secara keseluruhan telah meningkat secara substansial selama periode ini dari tahun 1960 hingga tahun 2105 di seluruh dunia. Dua kategori terbawah sekarang kosong, dan yang terendah [45,55] hanya berisi sejumlah kecil negara di dalamnya.
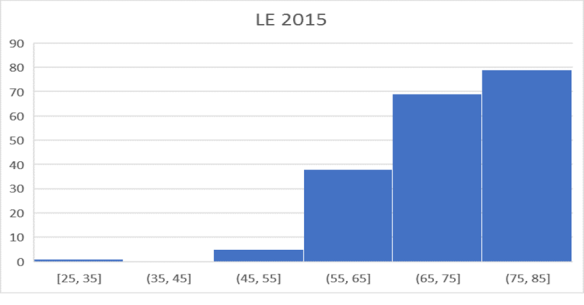
Catatan Penutup: Bapak Statistika Barat, Sir Roland Fisher, mendefinisikan statistika sebagai reduksi data. Kuncinya adalah menemukan “statistik yang memadai” – sejumlah kecil 'statistik' yang merangkum data. Hal ini dilakukan dengan memaksakan asumsi teoretis pada data. Misalnya, jika kita berasumsi bahwa datanya Normal, maka karya Fisher menunjukkan bahwa dua angka – mean dan deviasi standar – membawa informasi yang terkandung dalam seluruh kumpulan data. Inti pereduksian adalah kita tidak memiliki kapasitas mental untuk melihat 10.000 angka dalam kumpulan data dan memahaminya secara langsung. Namun, hari ini, dengan komputer, pendekatan alternatif dimungkinkan. Alih-alih memaksakan asumsi teoretis pada data, kita dapat membuat GRAFIK data dengan berbagai cara untuk mendapatkan gambaran yang dapat kita pahami. Tujuan Statistika Riil adalah LANGSUNG memvisualisasikan dan memahami data. Gambar-gambar ini akan digunakan untuk mendapatkan petunjuk tentang sifat realitas yang lebih dalam yang dimanifestasikan melalui angka. Harapan Hidup didasarkan pada tingkat kematian saat ini, dan peningkatan LE sesuai dengan penurunan tingkat kematian. Untuk mempelajari MENGAPA Harapan Hidup meningkat secara dramatis, kita harus mempelajari penyebab penurunan angka kematian di seluruh dunia. Penyebab-penyebab ini tidak tersedia dalam data, dan hanya dapat ditemukan dengan analisis kualitatif fitur-fitur dunia nyata yang telah menyebabkan meningkatnya harapan hidup.
3E Variasi Besaran Bin
Keterangan Awal: Mengira Peta sebagai Wilayah
Agar dapat memahami (menyederhanakan & mereduksi) data – sangat berguna untuk membuat model statistik untuk data tersebut. Jika data mengikuti distribusi teoretis, maka data tersebut dapat dijelaskan dengan rumus. DISTRIBUSI data dapat diidentifikasi dengan distribusi teoretis (seperti Normal). Jika benar, ia memungkinkan kita secara substansial mengurangi kumpulan data, karena distribusi Normal sepenuhnya dicirikan hanya oleh dua angka: mean dan deviasi standar.
Cara yang baik untuk mengidentifikasi distribusi Data adalah dengan melihat HISTOGRAM – gambaran data tersebut. Tapi, seperti yang akan kita lihat dalam bagian ini, ada banyak kemungkinan histogram untuk data, tergantung pada besaran bin. Sebuah pertanyaan lazim adalah: Apa model TERBAIK untuk data? Dalam konteks saat ini, berapa besaran bin terbaik untuk membuat histogram? Ini adalah pertanyaan yang SALAH. Data itu primer, model itu sekunder. Berbagai jenis model menggambarkan berbagai aspek data. Saat kita mengurangi besaran bin, kita mendapatkan gambaran data yang lebih halus. Pada setiap tingkat penyempurnaan – histogram menggambarkan berbagai aspek data. Tidak ada satu pun besaran bin TERBAIK. Kita akan mengilustrasikan konsep umum ini dengan membahas histogram Harapan Hidup bagi 190 negara dalam kumpulan data WDI untuk tahun 2018.
Kita mulai dengan melihat Histogram Asal bagi Harapan Hidup tahun 2018 untuk 190 negara dalam WDI. Histogram berubah dari MIN = 52.8 ke MAX = 85.0 berisi 7 bin dengan besaran yang sama, di mana Ukuran Bin = 4,6 tahun.
Dimulai dengan histogram ini sebagai kondisi awal, kita akan memeriksa efek dari membuat besaran bin lebih kecil atau lebih besar. Secara umum, jika besaran bin terlalu besar, semua data masuk ke satu bin, dan detailnya hilang. Di sisi lain, jika besaran bin terlalu kecil, setiap bin hanya berisi satu atau nol titik data dan pengelompokan dalam data tidak TERLIHAT dari grafik. 7 bin di atas adalah kompromi antara dua efek yang berlawanan ini, seperti yang akan segera kita lihat.
Kita mulai dengan Histogram Paling Kasar dengan Satu Bin Saja:

Dari sini, kita mempelajari KISARAN data: bervariasi dari MIN = 52,805 hingga MAX = 84,934. Ini adalah HITUNGAN histogram. kita belajar bahwa ada 190 negara dalam kumpulan data dari sumbu vertikal. Nanti kita akan mempelajari histogram PERSENTASE atau PROBABILITAS, yang memberi kita proporsi populasi dalam bin tertentu. Dari histogram probabilitas, kita tidak akan mempelajari hitungan, karena hanya 100% yang akan muncul pada sumbu vertikal.
Selanjutnya, mari kita lihat histogram dengan hanya dua bin:
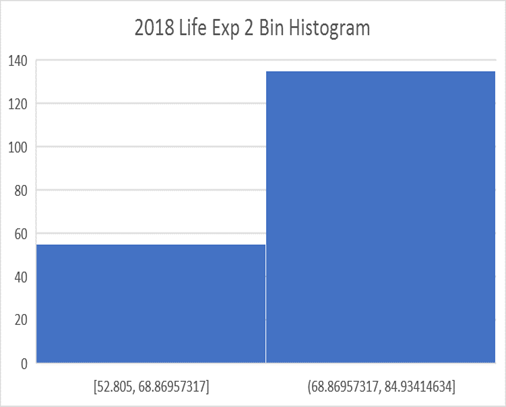
Dua Bin membagi rentang dari 52,8 hingga 84,9 tahun menjadi dua bagian yang sama. Titik tengah kisaran adalah 68,8 tahun. 55 negara berada dalam bin pertama di bawah titik tengah Harapan Hidup, sementara 135 negara dalam bin ke-2. Jelas, distribusinya TIDAK simetris. Dari grafik ini, jelas bahwa distribusi Normal TIDAK akan menjadi model yang tepat untuk kumpulan data ini.
Histogram 3 Bin membagi negara menjadi tiga kategori – Harapan Hidup tinggi, menengah, dan rendah. Bin LE Rendah berubah dari 52,8 menjadi 63,5 tahun, dan hanya berisi 27 negara. Bin LE tengah berubah dari 63,5 menjadi 74,2 tahun, dan berisi 71 negara. Tempat sampah LE tinggi berubah dari 74,2 menjadi 84,9 tahun, dan berisi 92 negara:
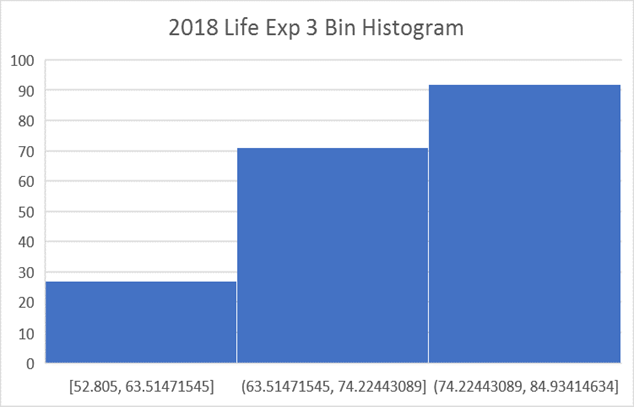
Yang sangat mengejutkan adalah jumlah negara terbanyak berada pada kategori tertinggi. MODUS adalah bin (atau kategori) yang memiliki jumlah kategori terbanyak. Grafik menunjukkan bahwa Modus berada dalam bin terakhir. MENGAPA temuan ini sangat mengejutkan? Ia akan menjadi jelas jika kita melihat histogram 190 negara yang sama yang diklasifikasikan berdasarkan GNP per kapita pada tahun 2018 yang sama. Grafiknya di bawah ini.
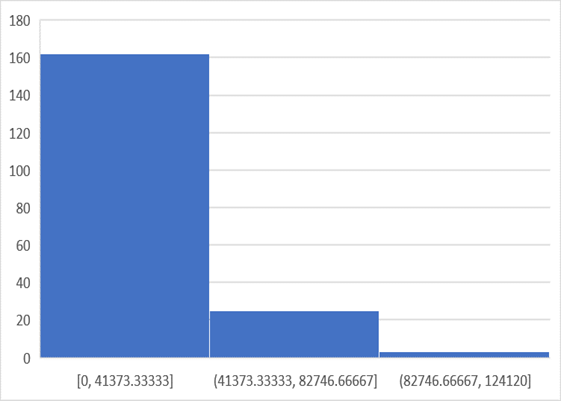
Histogram 3 bin dari GNP per kapita ini, dalam istilah PPP dengan USD konstan, menunjukkan bahwa hanya sedikit negara yang termasuk dalam kategori GNP tinggi, dan sebagian besar negara termasuk dalam kategori GNP rendah. Hal ini menunjukkan bahwa BAHKAN negara-negara dalam kategori pendapatan ketiga terbawah dapat mencapai angka harapan hidup yang tinggi bagi penduduknya. Artinya tindakan yang murah dan sederhana sudah cukup untuk menurunkan angka kematian secara substansial dan signifikan. Sebuah negara tidak perlu menunggu untuk menjadi kaya untuk mengambil langkah-langkah efektif yang meningkatkan kesehatan penduduk.
Histogram 4 Bin membagi rentang menjadi empat kategori, dengan Lebar Bin = 8 tahun:
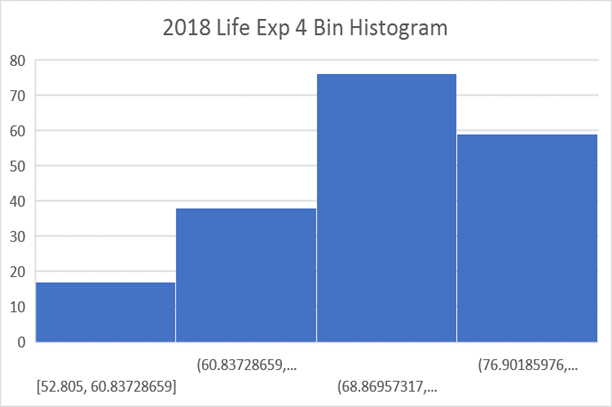
Dalam histogram ini, Bin Modus adalah [68.8, 76.9] dengan 75 negara. Hanya ada 59 negara dalam bin tertinggi, dari 76,9 menjadi 84,9 tahun. Grafik menunjukkan bahwa relatif mudah mendapatkan LE hingga 70 tahun, jauh lebih sulit untuk mendapatkan LE hingga 80 tahun. Untuk mempelajari lebih lanjut tentang hal ini, kita perlu melihat angka kematian dalam setiap kelompok usia. Dengan membandingkan antara negara-negara dengan tingkat kematian rendah dan tinggi, kita dapat belajar tentang potensi terbesar untuk perbaikan. Untuk mewujudkan potensi ini, kita perlu menyelidiki dengan cermat faktor-faktor penentu penyebab kematian.
Saat kita menelusuri grafik 5, 6, 7, 8, dan 10 bin, kita mendapatkan lebih banyak informasi tentang bagaimana data dapat dibagi menjadi berbagai jenis pengelompokan. Grafik 10 bin diplot di bawah ini:

Pada setiap tingkat penghalusan, kita mendapatkan lebih banyak informasi tentang data, dan kita juga mendapatkan beberapa pola visual yang tidak terlihat pada tingkat penghalusan lainnya. Namun, saat kita meningkatkan tingkat penghalusan, kita mulai kehilangan kemampuan melihat dan menafsirkan grafik secara langsung dan visual. Berikut adalah histogram dengan 20 bin:

Ada EMPAT modus dalam histogram ini. Ketika jumlah negara dalam bin kecil, suatu negara dapat jatuh ke dalam atau keluar bin secara statistika. Bila anda memiliki dua bin, Tinggi dan Rendah, klasifikasi akan tahan terhadap kesalahan kecil – terlepas dari cara anda menghitungnya, klasifikasi akan tetap sama untuk sebagian besar negara. Namun, ketika anda membuat banyak kategori, hal ini tidak lagi benar, dan klasifikasi bisa sangat dipengaruhi kesalahan kecil dalam data. Jadi jumlah negara yang ditampilkan dalam grafik itu RIUH – banyak dipengaruhi kesalahan. Saat kita membuat bin lebih kecil, keriuhan semakin meningkat dan pola data tidak lagi terlihat. Grafik dengan 40 bin sangat bergerigi dan riuh, dan pola yang lebih luas hampir tidak terlihat:
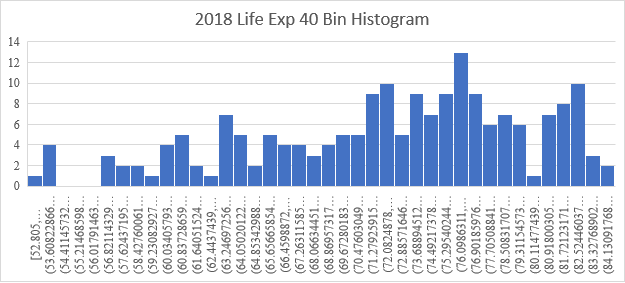
Dengan 100 bin, sangat sulit melihat pola apa pun dalam data yang mudah terlihat saat besaran bin lebih kecil:
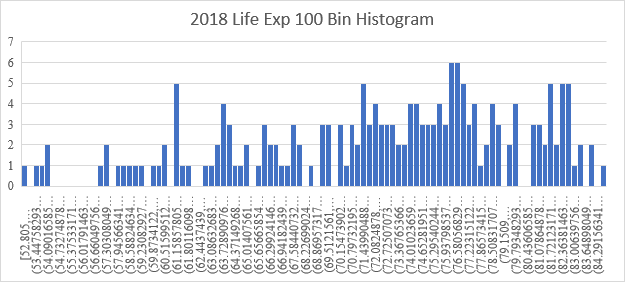
Jika kita membuat besaran bin lebih kecil, kita sampai pada titik di mana setiap bin berisi satu titik data, yang membuat pola agregat hampir mustahil untuk dilihat. Ada paradoks di sini. Secara teknis, semua data dalam bin kasar sebenarnya ada dalam bin halus. Hanya saja mata kita tidak mampu memproses informasi semacam ini dengan baik, kita tidak dapat mengubah gambar menjadi pola yang terlihat dalam histogram dengan besaran bin yang lebih besar. Besaran bin yang baik menyeimbangkan informasi objektif dengan kemampuan subjektif kita memproses informasi. Besaran bin bawaan yang dipilih oleh EXCEL memberikan gambaran data yang cukup baik. Perhatikan bahwa informasi dalam histogram menjadi terlihat SETELAH kita membuat grafik, jadi pilihan besaran bin yang “optimal” tidak mungkin. Pilihan besaran bin memberi kita Distribusi yang menyediakan MODEL untuk data, tetapi tidak ada model yang BENAR. Semua model adalah perkiraan untuk memungkinkan kita meringkas dan memahami data.
Pemahaman yang lebih dalam membutuhkan pemeriksaan tingkat kematian dan faktor-faktor penentu penyebabnya. Ini membutuhkan langkah lebih jauh, di luar kumpulan data, untuk memeriksa tingkat kematian, mengklasifikasikannya berdasarkan jenis, dan memeriksa penyebab setiap jenis. Angka memberi kita petunjuk tentang dunia nyata, tetapi tidak pernah menjadi tujuan analisis. Analisis statistika harus ditindaklanjuti dengan menelaah isu-isu dunia nyata yang disorotinya.
3F Histogram Probabilitas dan CDF
Tujuan buku ini adalah mengajarkan tentang statistika deskriptif sederhana, yang memungkinkan kita melihat dan memahami kumpulan data. Hubungan utama antara tujuan ini, dan konsep yang lebih rumit, adalah sampel acak. Bagian F dari bab 3 ini menjelaskan beberapa konsep paling dasar sehubungan sampel acak dari populasi objek di dunia nyata.
Konsep 1: Memilih salah satu anggota populasi “secara acak”. Kamus mendefinisikan "acak" sebagai: "dibuat, dilakukan, terjadi, atau dipilih tanpa metode atau keputusan sadar". Misalnya, saya dapat memilih negara secara acak dengan melemparkan panah ke peta dunia. Namun, ahli statistika menggunakan kata "acak" dalam arti teknis, yang sangat berbeda dengan penggunaan bahasa Inggris standar. Memilih secara acak berarti semua negara dalam populasi harus memiliki peluang yang sama untuk dipilih. Melempar anak panah tidak memungkinkan kita menghitung probabilitas seleksi setiap negara karena ada terlalu banyak variabel dan faktor subjektif, termasuk fakta bahwa negara yang berbeda memiliki ukuran yang berbeda. Cara yang masuk akal untuk memilih secara acak di antara 190 negara dalam daftar WDI adalah dengan memilih angka acak antara 1 dan 190 – misalnya, melalui fungsi EXCEL RANDBETWEEN(1.190). Fungsi ini memberikan kesempatan yang sama untuk semua angka dan jika sering diulang, akan membuat semua angka muncul sama seringnya dalam sampel besar. Adalah lazim mengacaukan dua pengertian kata ini, pilihan yang serampangan dalam bahasa Inggris (E-random), dan pilihan sistematis yang memberikan probabilitas sama untuk semua kemungkinan Statistik (S-random).
Konsep 2: Untuk menghubungkan pilihan S-acak dengan Histogram, pertimbangkan histogram tiga bin untuk 190 negara yang dibahas dalam kuliah sebelumnya. Bin RENDAH berubah dari 52,8 menjadi 63,5 tahun, dan berisi 27 negara. Bin TENGAH berubah dari 63,5 menjadi 74,2 tahun, dan berisi 71 negara. Bin TINGGI berubah dari 74,2 menjadi 84,9 tahun, dan berisi 92 negara. Histogram Probabilitas menjawab pertanyaan berikut: Jika sebuah negara dipilih secara acak dari populasi 190 negara ini, berapakah PROBABILITAS bahwa negara tersebut berada dalam salah satu dari tiga bin? Jawabannya jelas. Bin RENDAH berisi 27 negara, dan dengan demikian memiliki probabilitas 27/190 untuk dipilih. Bin TENGAH dan TINGGI masing-masing memiliki probabilitas 71/190, dan 92/190. Histogram ini digambarkan di bawah ini. Ini PERSIS sama dengan histogram 3-Bin pada bagian sebelumnya KECUALI untuk label pada Sumbu Vertikal. Histogram HITUNGAN memberi kita hitungan jumlah negara dalam setiap kategori. Histogram PROBABILITAS menggantikan hitungan dengan Persentase negara dalam setiap bin. Dalam histogram HITUNGAN, label sumbu adalah 10, 20, …, 100, sesuai dengan jumlah negara. Dalam histogram Probabilitas saat ini, angka-angka ini telah diganti dengan persentase yang sesuai dengan 10/190=5,3%, 20/190=10,5%, 30/190=15,8%,…,80/190=42,1%, 90/190=47,4 %, 100/190=52,6%. Jumlah negara telah dibagi dengan 190, jumlah total, untuk memberikan persentase dALAM setiap kategori,
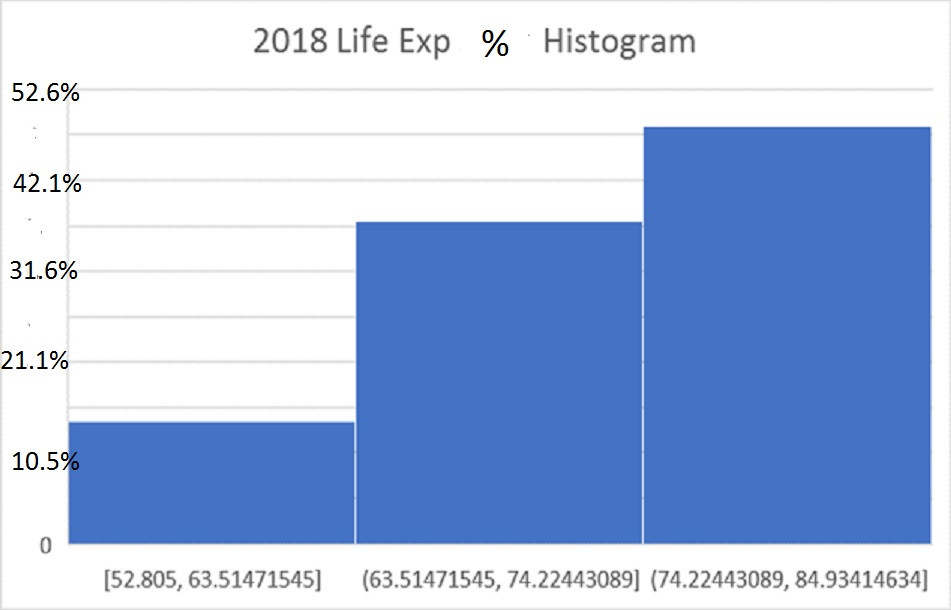
Anggap C menjadi negara yang dipilih secara acak dari antara 190 negara dalam sampel. Maka probabilitas histogram di atas memplot tiga probabilitas berikut: P(52.8 ≤LE(C) ≤ 63.5), P(63,5 < LE(C) 74,2), dan P(74,2 < LE(C)≤ 84,9). Ini adalah probabilitas negara yang dipilih secara acak yang memiliki harapan hidup dalam kisaran yang menentukan bin. Probabilitas ini menunjukkan "distribusi" variabel acak Harapan Hidup - ketinggian grafik memberi tahu kita peluang variabel acak berada dalam kisaran yang ditentukan. Untuk tujuan teoretis, Distribusi KUMULATIF ternyata menjadi konsep yang sangat penting. Alih-alih mencari probabilitas bin – P(a < LE(C) < b), distribusi kumulatif melihat SEMUA probabilitas hingga angka yang ditentukan: CDF(x) = P(LE(C) X).
Untuk menjelaskan fungsi distribusi kumulatif, berguna melihat kasus di mana hanya ada sedikit negara, karena membuat konsep lebih mudah dipahami dan divisualisasikan.
| 25 | Qatar | QAT | 81.0 |
| 84 | Turkey | TUR | 74.5 |
| 125 | Egypt | EGY | 69.9 |
| 169 | Afghanistan | AFG | 60.6 |
| 183 | Sudan | SDN | 56.1 |
Asumsikan bahwa lima negara ini, yang dipilih secara "E-random" (dalam arti bahasa Inggris) dari 190 negara, adalah populasi penuh negara. Kita akan memilih negara secara S-random dari 5 negara ini, dan menyebutnya C. LE(C) mewakili Harapan Hidup dari negara yang dipilih secara acak. Karakteristik negara yang dipilih secara acak, seperti LE, disebut variabel acak. Untuk sembarang bilangan real x, kita ingin mengukur P(LE(C)≤ x) – ini adalah, secara definisi, fungsi distribusi kumulatif dari variabel acak LE(C). Ia dapat dengan mudah diplot sebagai berikut.

Untuk semua nilai x kurang dari 56,1, probabilitas bahwa Harapan Hidup dari negara yang dipilih secara acak lebih kecil dari x ini adalah 0%. Grafik menunjukkan bahwa P(LE(C)≤x) = 0% pada anak tangga pertama grafik. Sebabnya adalah Sudan memiliki LE sebesar 56,1 tahun yang merupakan LE terkecil dalam kumpulan data. Untuk nilai x antara 56,1 dan 60,6 tahun, P( LE(C)≤x) adalah 20%. Hanya ada satu negara (Sudan) yang memiliki LE di bawah kisaran nilai ini. Peluang memilih Sudan secara acak adalah 1 dari 5 atau 20%. Demikian pula, untuk nilai x antara 60,6 dan 69,9 tahun, P(LE(C)≤x) = 40%. Untuk nilai x dalam rentang ini, ada dua negara, Sudan dan Afghanistan, yang memiliki LE di bawah x. Peluang memilih salah satu dari dua negara ini dari pilihan acak antara 5 negara persis 2/5 atau 40%. Demikian pula, grafik melonjak sebesar 20% pada Harapan Hidup masing-masing dari lima negara dalam kumpulan data. Deskripsi singkat ini memberikan pengenalan awal konsep fungsi distribusi kumulatif. Rincian lebih lanjut akan dibahas dalam bagian berikutnya, di mana ide-ide pengambilan sampel acak, yang merupakan inti dari teori statistika, akan dikembangkan. Dalam bagian ini, kita hanya membahas grafik yang berbeda yang mewakili data dengan cara yang berbeda. CDF data, seperti gambar di atas, juga merupakan salah satu cara membuat grafik data.
Sumber gambar: Tangkapan layar halaman judul pada tautan https://onedrive.live.com/view.aspx?resid=F5F6A4108BE920A5!52156&ithint=file%2cdocx&authkey=!AHytrdUzCrHN0Z8
Karya ini GRATIS! Tapi kamu boleh kok kasih tip biar kreator hepi 🥰
